Much of the research in our lab centers around prosody, the interpretation of intent based on vocal modulation through changes in perceived pitch, voice intensity, voice quality and speech rate. Prosody is an invaluable tool to attribute emotions to other’s voices. In our evolutionary past, perceiving prosody allowed our ancestors to determine friend or foe, securing survival by means of enhanced social communication. Even with the new reliance on digital communication, prosody is just as relevant. Has someone ever misconstrued a text message as serious even though you meant it jokingly? Prosody is responsible for distinguishing sarcasm and the differentiation between a question and a statement. Without prosody, we would all sound like HAL from 2001, A Space Odyssey:
Researchers explored the specific cues that signal emotional intent and discovered that the acoustical signatures of primary emotional intents, such as happiness, fear, and anger, in prosodic utterances tend to differ from one another. The acoustic features of prosody and their pattern across primary emotions are portrayed in the table below:
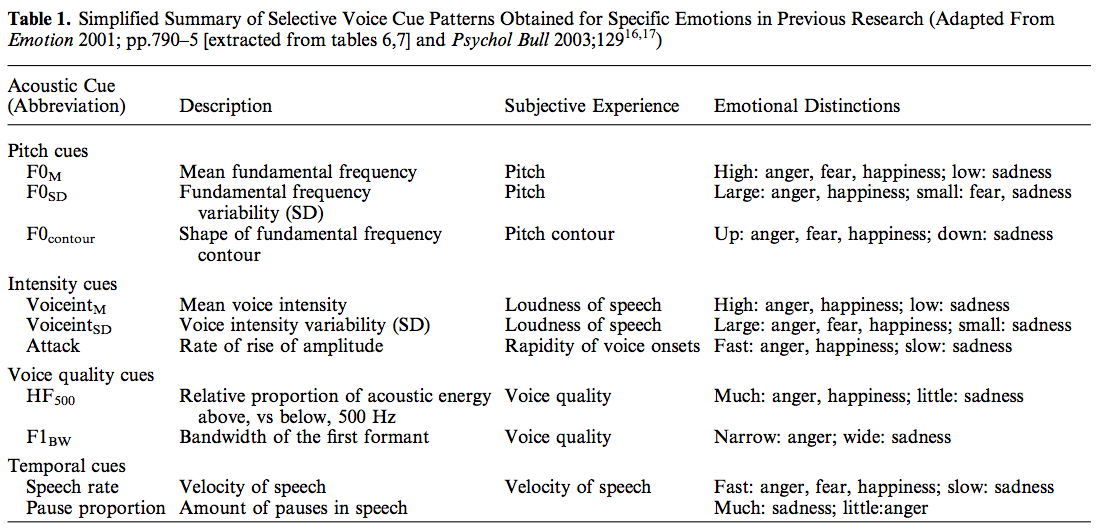
Prior study indicated that F0SD levels for both fear and happiness stimuli and HF500 for anger stimuli had distinct ranges that differentiated them from other emotional categories. Utilizing this information, Juslin and Laukka (2001) were able to devise stimuli using actors speaking semantically neutral sentences into the Auditory Emotion Recognition (AER) task, or Laukka Prosody task. We use a subset of these stimuli in . Within each emotional stimulus group, a clear relationship between acoustic cue level and probability of correctly identifying the emotional target was observed. Z-transforming each cue value within each emotion enables us to create a vector ZCUE reflecting Cue Saliency, the relative cue level or degree of ambiguity within each stimulus in terms of its emotional categories. Utilizing this information, Juslin and Laukka (2001) were able to devise stimuli using actors speaking semantically neutral sentences into the Auditory Emotion Recognition (AER) task, or Laukka Prosody task. We use a subset of these stimuli in our lab. 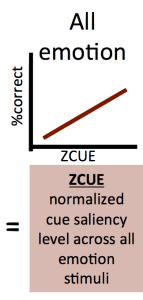 Within each emotional stimulus group, a clear relationship between acoustic cue level and probability of correctly identifying the emotional target was observed. Z-transforming each cue value within each emotion enables us to create a vector ZCUE reflecting Cue Saliency, the relative cue level or degree of ambiguity within each stimulus in terms of its emotional
Within each emotional stimulus group, a clear relationship between acoustic cue level and probability of correctly identifying the emotional target was observed. Z-transforming each cue value within each emotion enables us to create a vector ZCUE reflecting Cue Saliency, the relative cue level or degree of ambiguity within each stimulus in terms of its emotional
intent.
Below, you can listen to 2 separate stimuli. The first is a “low” cue saliency – it was identified as happy only 25% of the time. The second has high cue saliency – it was identified as happy 91% of the time.
Pitch Dysfunction
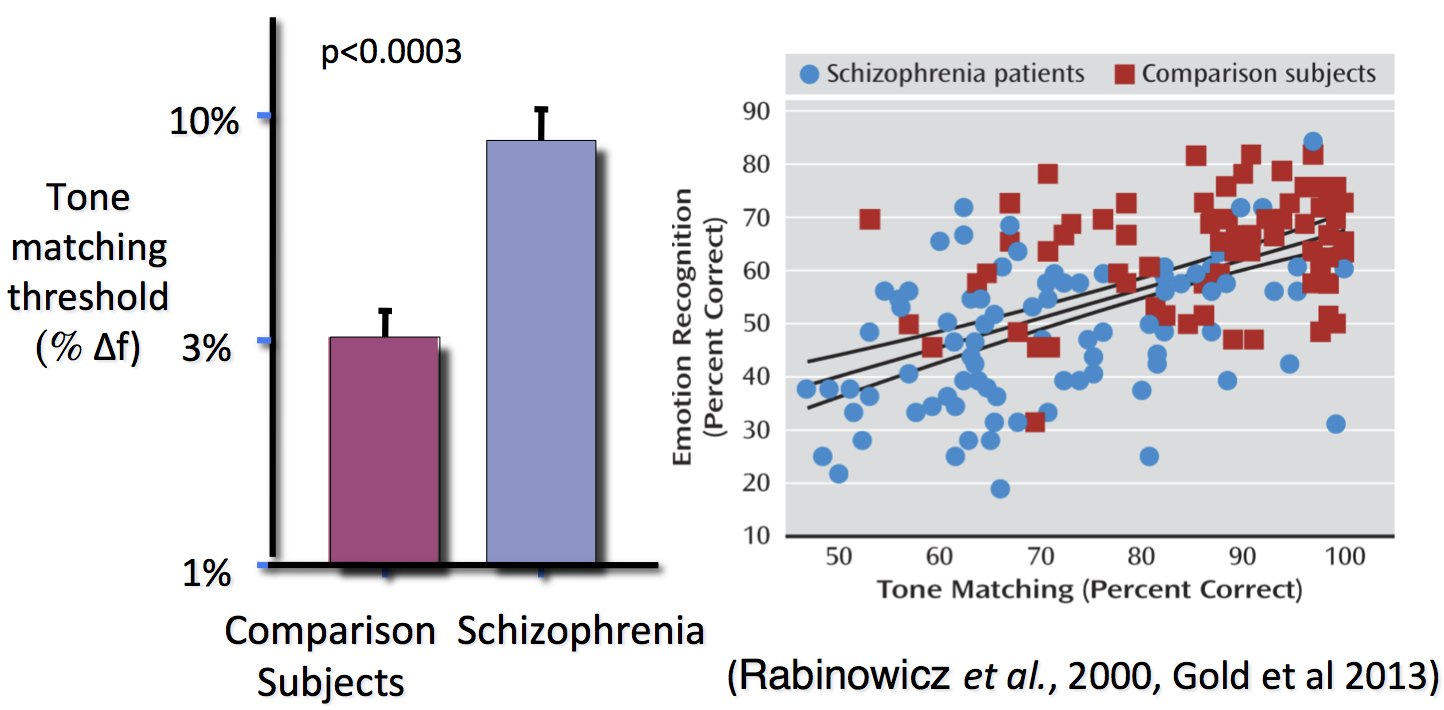
It is widely accepted that individuals with schizophrenia have impaired pitch perception. These individuals actually need over 3 times the frequency difference of healthy individuals to reliably discriminate tones. When considering the importance of pitch cues in prosody, it is easy to see how pitch dysfunction could translate into prosody dysfunction.
Prosody Dysfunction
Considering its importance in social communication, a deficit in prosody perception could be detrimental to social functioning. Imagine how you would converse with others if everyone else essentially sounded like HAL. Schizophrenia, autism spectrum disorders, and Parkinson’s disease are some of the disorders associated with prosody dysfunction. However, exactly where this deficit lies is currently unclear. The process between hearing someone’s voice and attributing an emotion to the person involves multiple functions:
Affective prosodic processing model and the temporo-frontal reciprocal processing network

First, the stimulus undergoes low level auditory processing. We extract cues like pitch, intensity, and the spectrum and integrate them together in an attempt to evaluate the meaning of the cues and attribute the emotion. To complicate things further, this can be both a top-down and bottom-up process. A disruption could occur during any point in this process to impair the ability to accurately perceive and evaluate prosodic cues. We hypothesize that stimuli with greater cue saliency will be more easily recognized and thus will result in increased facilitation of feature extraction and integration, while lower cue saliency may require more evaluation and result in top-down modulation. By exploring this relationship in these disorders, we may be better able to pinpoint exactly where the deficits lie, thereby determining where to target remediation interventions.
Comments are closed.